2026
CodecFake+: Codec-Based Resynthesized Data as a Proxy for Detecting CodecFake Speech
Jiawei Du*, Xuanjun Chen*, Haibin Wu, Lin Zhang, I-Ming Lin, I-Hsiang Chiu, Wenze Ren, Yuan Tseng, Yu Tsao, Jyh-Shing Roger Jang, Hung-Yi Lee (* equal contribution)
IEEE Transactions on Audio, Speech and Language Processing (TASLP) 2026
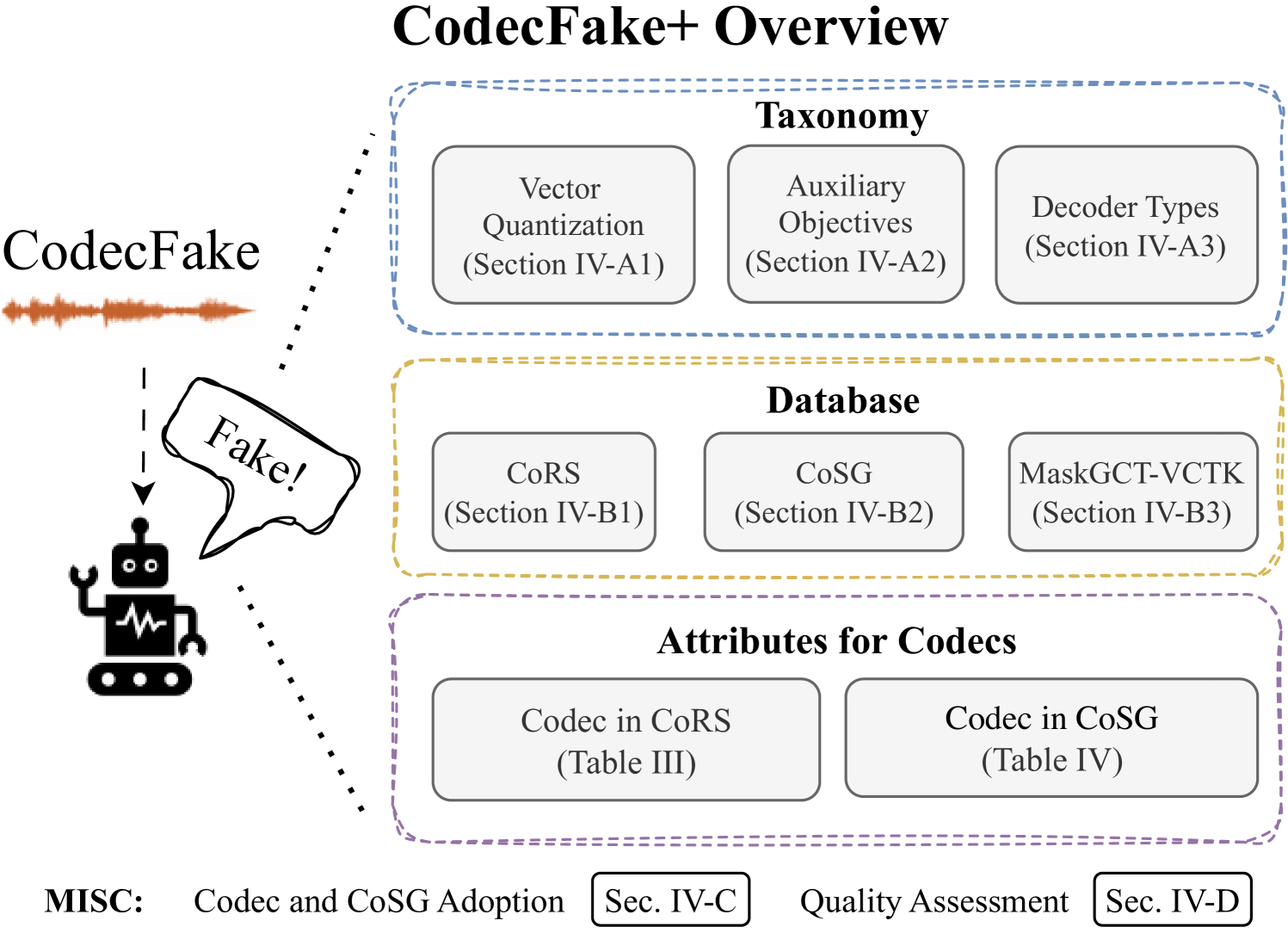
CodecFake+ is a large-scale dataset and taxonomy for detecting codec-based deepfake speech generated by neural audio codecs. It provides diverse training and evaluation data across many codec architectures and enables more systematic analysis for building stronger audio anti-spoofing models.
CodecFake+: Codec-Based Resynthesized Data as a Proxy for Detecting CodecFake Speech
Jiawei Du*, Xuanjun Chen*, Haibin Wu, Lin Zhang, I-Ming Lin, I-Hsiang Chiu, Wenze Ren, Yuan Tseng, Yu Tsao, Jyh-Shing Roger Jang, Hung-Yi Lee (* equal contribution)
IEEE Transactions on Audio, Speech and Language Processing (TASLP) 2026
CodecFake+ is a large-scale dataset and taxonomy for detecting codec-based deepfake speech generated by neural audio codecs. It provides diverse training and evaluation data across many codec architectures and enables more systematic analysis for building stronger audio anti-spoofing models.

Localizing Audio-Visual Deepfakes via Hierarchical Boundary Modeling
Xuanjun Chen*, Shih-Peng Cheng*, Jiawei Du, Lin Zhang, Xiaoxiao Miao, Chung-Che Wang, Haibin Wu, Hung-Yi Lee, Jyh-Shing Roger Jang (* equal contribution)
Submitted to ISCSLP 2026
This paper proposes HBMNet, a hierarchical boundary modeling network for localizing partially manipulated audio-visual deepfakes. By combining dedicated audio-visual encoding and fusion, frame-level supervision, multi-scale temporal modeling, and bidirectional boundary-content reasoning, it achieves better localization performance than prior methods such as BA-TFD and UMMAFormer.
Localizing Audio-Visual Deepfakes via Hierarchical Boundary Modeling
Xuanjun Chen*, Shih-Peng Cheng*, Jiawei Du, Lin Zhang, Xiaoxiao Miao, Chung-Che Wang, Haibin Wu, Hung-Yi Lee, Jyh-Shing Roger Jang (* equal contribution)
Submitted to ISCSLP 2026
This paper proposes HBMNet, a hierarchical boundary modeling network for localizing partially manipulated audio-visual deepfakes. By combining dedicated audio-visual encoding and fusion, frame-level supervision, multi-scale temporal modeling, and bidirectional boundary-content reasoning, it achieves better localization performance than prior methods such as BA-TFD and UMMAFormer.
2025

Codec-Based Deepfake Source Tracing via Neural Audio Codec Taxonomy
Xuanjun Chen*, I-Ming Lin*, Lin Zhang, Jiawei Du, Haibin Wu, Hung-Yi Lee, Jyh-Shing Roger Jang (* equal contribution)
Interspeech 2025
This paper introduces source tracing for codec-based deepfake speech by leveraging a taxonomy of neural audio codecs used in codec-based speech generation systems. Experiments on the CodecFake+ dataset show promising initial feasibility for tracing the source model behind deepfake speech while also revealing several open challenges.
Codec-Based Deepfake Source Tracing via Neural Audio Codec Taxonomy
Xuanjun Chen*, I-Ming Lin*, Lin Zhang, Jiawei Du, Haibin Wu, Hung-Yi Lee, Jyh-Shing Roger Jang (* equal contribution)
Interspeech 2025
This paper introduces source tracing for codec-based deepfake speech by leveraging a taxonomy of neural audio codecs used in codec-based speech generation systems. Experiments on the CodecFake+ dataset show promising initial feasibility for tracing the source model behind deepfake speech while also revealing several open challenges.
2024
Codec-SUPERB @ SLT 2024: A Lightweight Benchmark for Neural Audio Codec Models
Haibin Wu, Jiawei Du*, Xuanjun Chen*, Yi-Cheng Lin*, Kai-Wei Chang*, Ke-Han Lu*, Alexander H. Liu*, Ho-Lam Chung*, Yuan-Kuei Wu*, Dongchao Yang*, Songxiang Liu, Yi-Chiao Wu, Xu Tan, James Glass, Shinji Watanabe, Hung-Yi Lee (* equal contribution)
IEEE Spoken Language Technology Workshop (SLT) 2024 Special Session
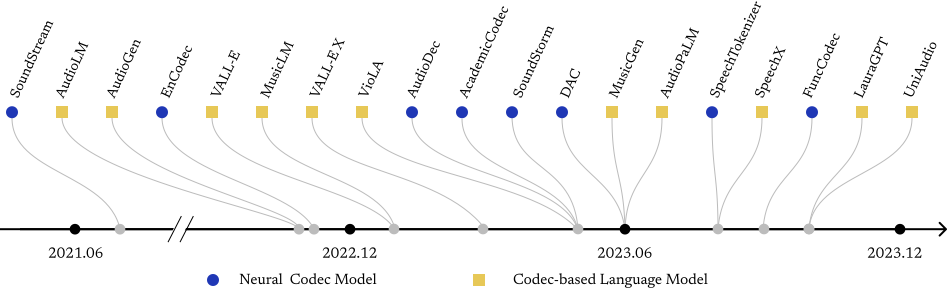
Codec-SUPERB introduces a lightweight and standardized benchmark for evaluating neural audio codec models across multiple speech tasks. It enables fair comparison under consistent settings and reveals key trade-offs in preserving linguistic content, speaker characteristics, and audio quality at low bitrates.
Codec-SUPERB @ SLT 2024: A Lightweight Benchmark for Neural Audio Codec Models
Haibin Wu, Jiawei Du*, Xuanjun Chen*, Yi-Cheng Lin*, Kai-Wei Chang*, Ke-Han Lu*, Alexander H. Liu*, Ho-Lam Chung*, Yuan-Kuei Wu*, Dongchao Yang*, Songxiang Liu, Yi-Chiao Wu, Xu Tan, James Glass, Shinji Watanabe, Hung-Yi Lee (* equal contribution)
IEEE Spoken Language Technology Workshop (SLT) 2024 Special Session
Codec-SUPERB introduces a lightweight and standardized benchmark for evaluating neural audio codec models across multiple speech tasks. It enables fair comparison under consistent settings and reveals key trade-offs in preserving linguistic content, speaker characteristics, and audio quality at low bitrates.

Empower Typed Descriptions by Large Language Models for Speech Emotion Recognition
Haibin Wu*, Huang-Cheng Chou*, Kai-Wei Chang, Lucas Goncalves, Jiawei Du, Jyh-Shing Roger Jang, Chi-Chun Lee, Hung-Yi Lee (* equal contribution)
APSIPA ASC 2024
This work leverages large language models to process natural language typed descriptions in speech emotion datasets and refine emotion label distributions. By using ChatGPT to relabel data, it consistently improves speech emotion recognition performance across multiple self-supervised speech models.
Empower Typed Descriptions by Large Language Models for Speech Emotion Recognition
Haibin Wu*, Huang-Cheng Chou*, Kai-Wei Chang, Lucas Goncalves, Jiawei Du, Jyh-Shing Roger Jang, Chi-Chun Lee, Hung-Yi Lee (* equal contribution)
APSIPA ASC 2024
This work leverages large language models to process natural language typed descriptions in speech emotion datasets and refine emotion label distributions. By using ChatGPT to relabel data, it consistently improves speech emotion recognition performance across multiple self-supervised speech models.
DFADD: The Diffusion and Flow-Matching Based Audio Deepfake Dataset
Jiawei Du*, I-Ming Lin*, I-Hsiang Chiu*, Xuanjun Chen, Haibin Wu, Wenze Ren, Yu Tsao, Hung-Yi Lee, Jyh-Shing Roger Jang (* equal contribution)
IEEE Spoken Language Technology Workshop (SLT) 2024
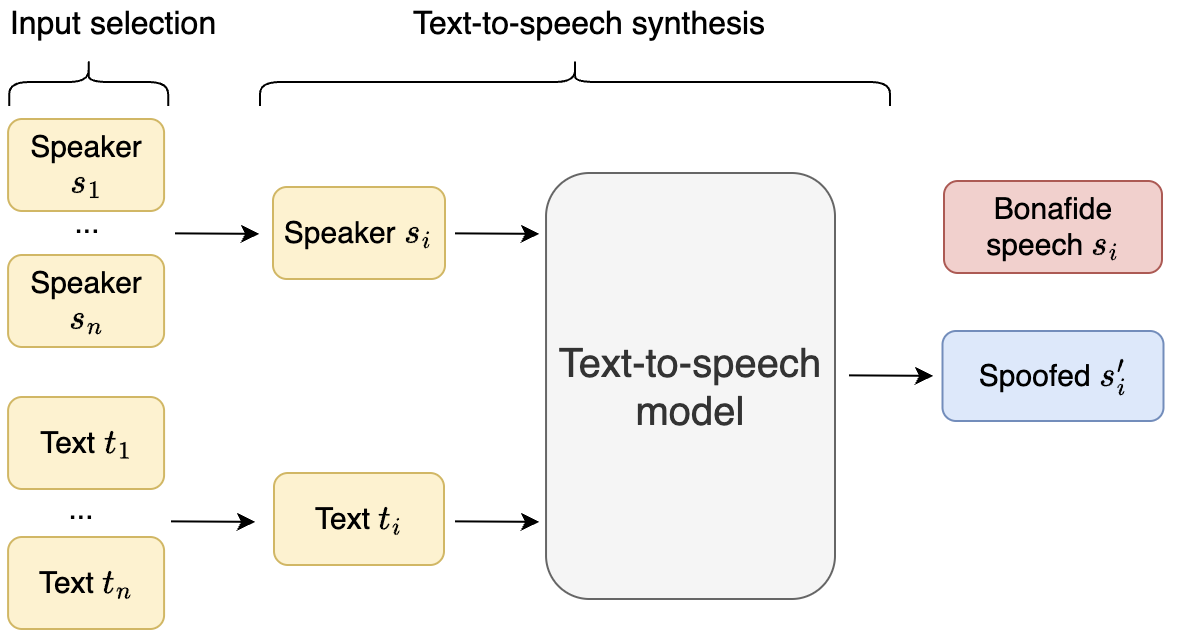
DFADD is the first dataset for audio deepfake detection that focuses on speech synthesized by diffusion- and flow-matching-based TTS models, and reveals that current anti-spoofing systems still struggle with these more realistic fake audios.
DFADD: The Diffusion and Flow-Matching Based Audio Deepfake Dataset
Jiawei Du*, I-Ming Lin*, I-Hsiang Chiu*, Xuanjun Chen, Haibin Wu, Wenze Ren, Yu Tsao, Hung-Yi Lee, Jyh-Shing Roger Jang (* equal contribution)
IEEE Spoken Language Technology Workshop (SLT) 2024
DFADD is the first dataset for audio deepfake detection that focuses on speech synthesized by diffusion- and flow-matching-based TTS models, and reveals that current anti-spoofing systems still struggle with these more realistic fake audios.

Open-Emotion: A Reproducible EMO-SUPERB for Speech Emotion Recognition Systems
Haibin Wu*, Huang-Cheng Chou*, Kai-Wei Chang, Lucas Goncalves, Jiawei Du, Jyh-Shing Roger Jang, Chi-Chun Lee, Hung-Yi Lee (* equal contribution)
APSIPA ASC 2024
Open-Emotion provides a reproducible EMO-SUPERB benchmark for speech emotion recognition, with unified dataset partitions, an easy-to-use codebase, and a community-driven leaderboard. It enables fair comparison across 16 SSL speech models and multiple public SER datasets while addressing common reproducibility and data leakage issues.
Open-Emotion: A Reproducible EMO-SUPERB for Speech Emotion Recognition Systems
Haibin Wu*, Huang-Cheng Chou*, Kai-Wei Chang, Lucas Goncalves, Jiawei Du, Jyh-Shing Roger Jang, Chi-Chun Lee, Hung-Yi Lee (* equal contribution)
APSIPA ASC 2024
Open-Emotion provides a reproducible EMO-SUPERB benchmark for speech emotion recognition, with unified dataset partitions, an easy-to-use codebase, and a community-driven leaderboard. It enables fair comparison across 16 SSL speech models and multiple public SER datasets while addressing common reproducibility and data leakage issues.

Neural Codec-based Adversarial Sample Detection for Speaker Verification
Jiawei Du*, Xuanjun Chen*, Haibin Wu, Jyh-Shing Roger Jang, Hung-Yi Lee (* equal contribution)
Interspeech 2024
This paper proposes a neural codec-based method to detect adversarial samples for speaker verification by comparing ASV score differences before and after codec re-synthesis. Experiments across 15 open-source neural codecs show that the approach outperforms seven prior baselines, with Descript Audio Codec giving the best results.
Neural Codec-based Adversarial Sample Detection for Speaker Verification
Jiawei Du*, Xuanjun Chen*, Haibin Wu, Jyh-Shing Roger Jang, Hung-Yi Lee (* equal contribution)
Interspeech 2024
This paper proposes a neural codec-based method to detect adversarial samples for speaker verification by comparing ASV score differences before and after codec re-synthesis. Experiments across 15 open-source neural codecs show that the approach outperforms seven prior baselines, with Descript Audio Codec giving the best results.

EMO-SUPERB: An in-depth look at speech emotion recognition
Haibin Wu*, Huang-Cheng Chou*, Kai-Wei Chang, Lucas Goncalves, Jiawei Du, Jyh-Shing Roger Jang, Chi-Chun Lee, Hung-Yi Lee (* equal contribution)
arXiv preprint 2024
EMO-SUPERB is an open benchmark for speech emotion recognition that evaluates 15 SSL speech models across six datasets and improves reproducibility in SER research. It shows that leveraging LLM to relabel natural-language emotion annotations can consistently improve performance over standard label-only training.
EMO-SUPERB: An in-depth look at speech emotion recognition
Haibin Wu*, Huang-Cheng Chou*, Kai-Wei Chang, Lucas Goncalves, Jiawei Du, Jyh-Shing Roger Jang, Chi-Chun Lee, Hung-Yi Lee (* equal contribution)
arXiv preprint 2024
EMO-SUPERB is an open benchmark for speech emotion recognition that evaluates 15 SSL speech models across six datasets and improves reproducibility in SER research. It shows that leveraging LLM to relabel natural-language emotion annotations can consistently improve performance over standard label-only training.
2023

DCASE 2023 Task 6B: Text-to-Audio Retrieval Using Pretrained Models
Jiawei Du*, Chung-Che Wang*, Jyh-Shing Roger Jang (* equal contribution)
DCASE Challenge Technical Report 2023 3rd Place
This report presents the third-place system for DCASE 2023 Task 6B on text-to-audio retrieval. It adopts a bi-encoder framework with pretrained audio and text encoders and explores different architectures, data augmentation, and auxiliary-task strategies.
DCASE 2023 Task 6B: Text-to-Audio Retrieval Using Pretrained Models
Jiawei Du*, Chung-Che Wang*, Jyh-Shing Roger Jang (* equal contribution)
DCASE Challenge Technical Report 2023 3rd Place
This report presents the third-place system for DCASE 2023 Task 6B on text-to-audio retrieval. It adopts a bi-encoder framework with pretrained audio and text encoders and explores different architectures, data augmentation, and auxiliary-task strategies.