
Georgia Institute of Technology
AI Virtual Assistant (AVA) Lab
Hi! I am Jiawei Du, a Ph.D. student in the School of Electrical and Computer Engineering at Georgia Tech, advised by Dr. Larry Heck. My research interests lie in speech and audio processing, particularly audio large language models for real-time conversational and multi-party speech understanding.
Before joining Georgia Tech, I was a Research Assistant in the Graduate Institute of Networking and Multimedia at National Taiwan University, supervised by Dr. Hung-Yi Lee. I received my M.S. degree in Computer Science and Information Engineering from National Taiwan University, where I was advised by Dr. Jyh-Shing Roger Jang and worked closely with Dr. Hung-Yi Lee on audio coding and anti-spoofing. During my graduate studies, I was a Research Intern at Samsung Research SRC-B, focusing on streaming and lightweight neural audio codecs. Prior to that, I earned my B.S. degree (ranked 1st/79) in Information and Telecommunications Engineering (now Electrical Engineering) from Ming Chuan University, supervised by Dr. Shu-Yin Chiang. I also completed an exchange program in Computer Science and Engineering at Shanghai Jiao Tong University.
Education
-
 Georgia Institute of TechnologyAtlantaIncoming Ph.D. Student
Georgia Institute of TechnologyAtlantaIncoming Ph.D. Student
School of Electrical and Computer EngineeringAug. 2026 - present -
 National Taiwan UniversityTaipeiM.S. in Computer Science and Information EngineeringSep. 2022 - Jun. 2025
National Taiwan UniversityTaipeiM.S. in Computer Science and Information EngineeringSep. 2022 - Jun. 2025 -
 Ming Chuan UniversityTaoyuanB.S. in Information and Telecommunications EngineeringSep. 2018 - Jun. 2022
Ming Chuan UniversityTaoyuanB.S. in Information and Telecommunications EngineeringSep. 2018 - Jun. 2022
Experience
-
National Taiwan UniversityTaipeiResearch Assistant
Speech Processing and Machine Learning LabSep. 2025 - Aug. 2026 -
 Samsung Research SRC-BBeijingResearch Intern in Speech TeamFeb. 2025 - May. 2025
Samsung Research SRC-BBeijingResearch Intern in Speech TeamFeb. 2025 - May. 2025 -
 Shanghai Jiao Tong UniversityShanghaiExchange Student in Computer Science and EngineeringSep. 2020 - Jan. 2021
Shanghai Jiao Tong UniversityShanghaiExchange Student in Computer Science and EngineeringSep. 2020 - Jan. 2021
News
Selected Publications (view all )
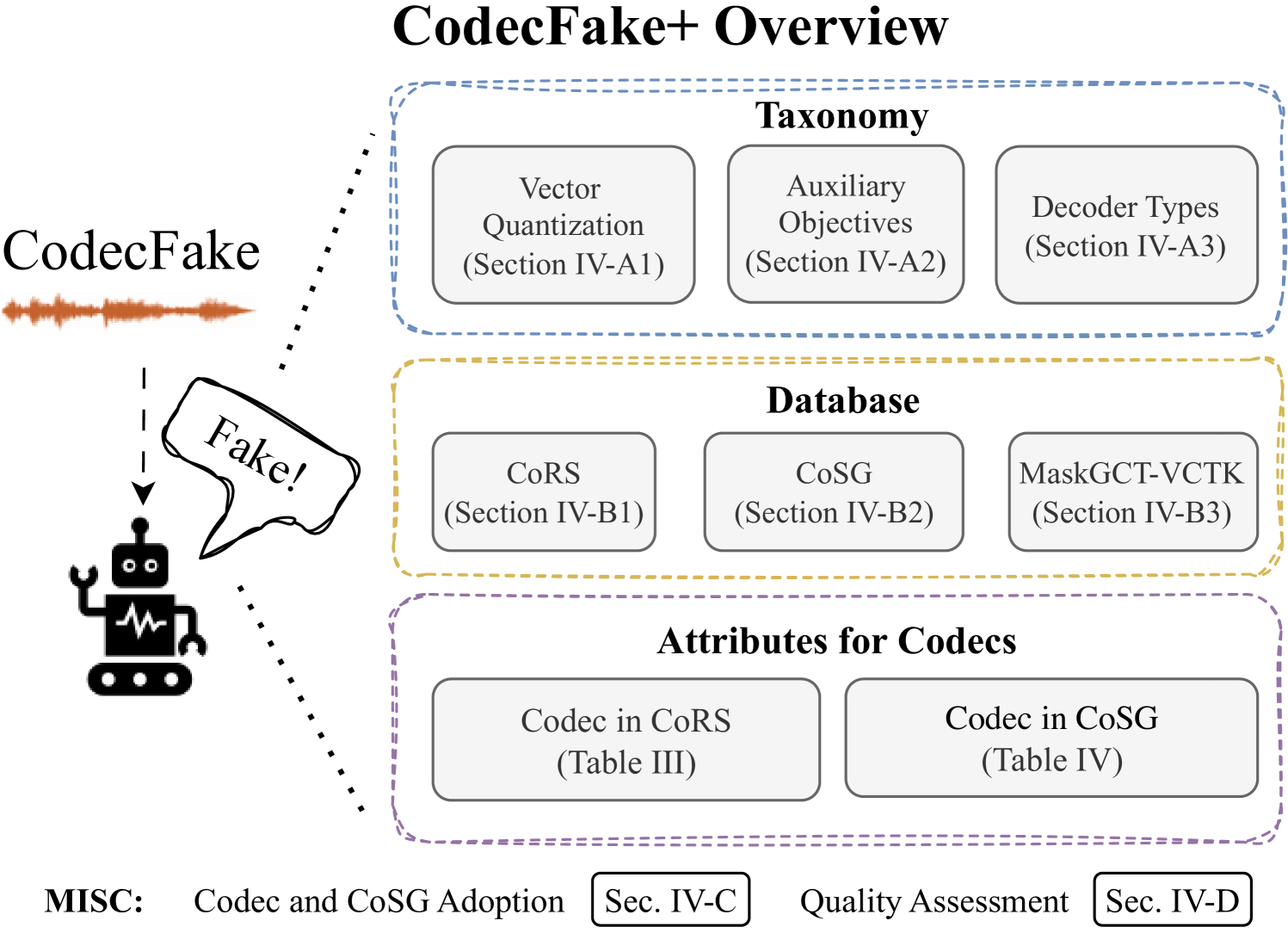
CodecFake+: Codec-Based Resynthesized Data as a Proxy for Detecting CodecFake Speech
Jiawei Du*, Xuanjun Chen*, Haibin Wu, Lin Zhang, I-Ming Lin, I-Hsiang Chiu, Wenze Ren, Yuan Tseng, Yu Tsao, Jyh-Shing Roger Jang, Hung-Yi Lee (* equal contribution)
IEEE Transactions on Audio, Speech and Language Processing (TASLP) 2026
CodecFake+ is a large-scale dataset and taxonomy for detecting codec-based deepfake speech generated by neural audio codecs. It provides diverse training and evaluation data across many codec architectures and enables more systematic analysis for building stronger audio anti-spoofing models.
CodecFake+: Codec-Based Resynthesized Data as a Proxy for Detecting CodecFake Speech
Jiawei Du*, Xuanjun Chen*, Haibin Wu, Lin Zhang, I-Ming Lin, I-Hsiang Chiu, Wenze Ren, Yuan Tseng, Yu Tsao, Jyh-Shing Roger Jang, Hung-Yi Lee (* equal contribution)
IEEE Transactions on Audio, Speech and Language Processing (TASLP) 2026
CodecFake+ is a large-scale dataset and taxonomy for detecting codec-based deepfake speech generated by neural audio codecs. It provides diverse training and evaluation data across many codec architectures and enables more systematic analysis for building stronger audio anti-spoofing models.
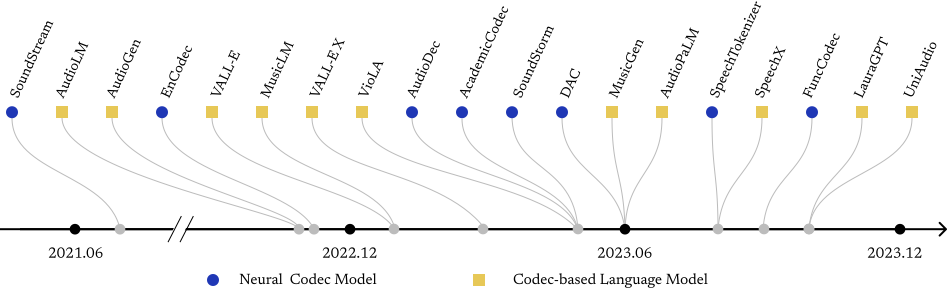
Codec-SUPERB @ SLT 2024: A Lightweight Benchmark for Neural Audio Codec Models
Haibin Wu, Jiawei Du*, Xuanjun Chen*, Yi-Cheng Lin*, Kai-Wei Chang*, Ke-Han Lu*, Alexander H. Liu*, Ho-Lam Chung*, Yuan-Kuei Wu*, Dongchao Yang*, Songxiang Liu, Yi-Chiao Wu, Xu Tan, James Glass, Shinji Watanabe, Hung-Yi Lee (* equal contribution)
IEEE Spoken Language Technology Workshop (SLT) 2024 Special Session
Codec-SUPERB introduces a lightweight and standardized benchmark for evaluating neural audio codec models across multiple speech tasks. It enables fair comparison under consistent settings and reveals key trade-offs in preserving linguistic content, speaker characteristics, and audio quality at low bitrates.
Codec-SUPERB @ SLT 2024: A Lightweight Benchmark for Neural Audio Codec Models
Haibin Wu, Jiawei Du*, Xuanjun Chen*, Yi-Cheng Lin*, Kai-Wei Chang*, Ke-Han Lu*, Alexander H. Liu*, Ho-Lam Chung*, Yuan-Kuei Wu*, Dongchao Yang*, Songxiang Liu, Yi-Chiao Wu, Xu Tan, James Glass, Shinji Watanabe, Hung-Yi Lee (* equal contribution)
IEEE Spoken Language Technology Workshop (SLT) 2024 Special Session
Codec-SUPERB introduces a lightweight and standardized benchmark for evaluating neural audio codec models across multiple speech tasks. It enables fair comparison under consistent settings and reveals key trade-offs in preserving linguistic content, speaker characteristics, and audio quality at low bitrates.
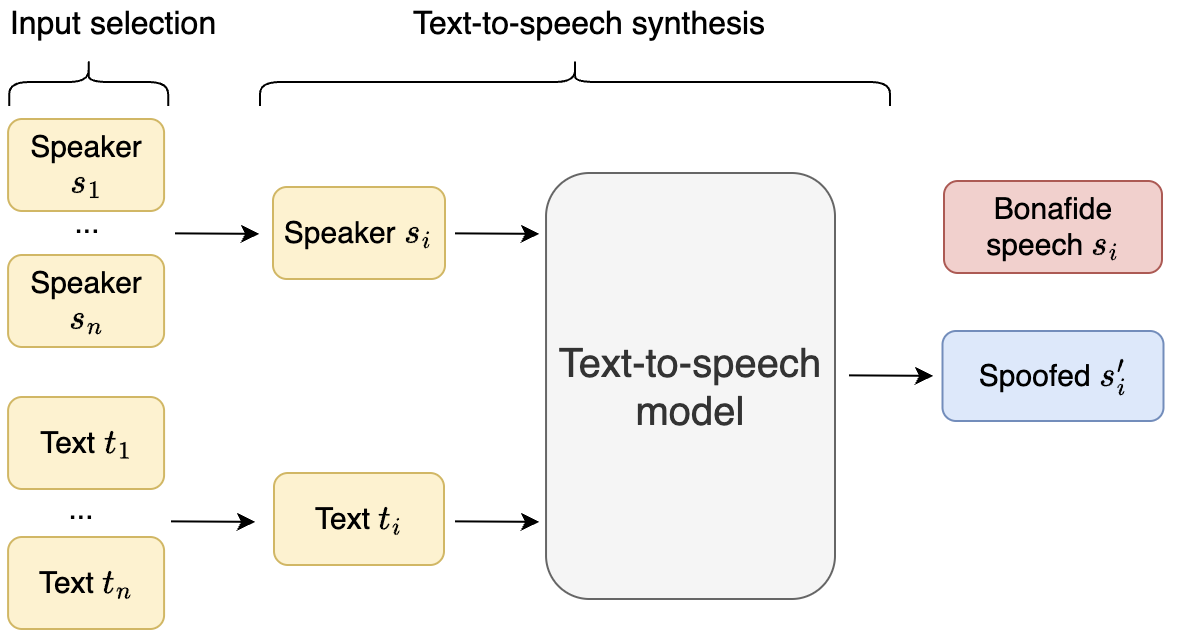
DFADD: The Diffusion and Flow-Matching Based Audio Deepfake Dataset
Jiawei Du*, I-Ming Lin*, I-Hsiang Chiu*, Xuanjun Chen, Haibin Wu, Wenze Ren, Yu Tsao, Hung-Yi Lee, Jyh-Shing Roger Jang (* equal contribution)
IEEE Spoken Language Technology Workshop (SLT) 2024
DFADD is the first dataset for audio deepfake detection that focuses on speech synthesized by diffusion- and flow-matching-based TTS models, and reveals that current anti-spoofing systems still struggle with these more realistic fake audios.
DFADD: The Diffusion and Flow-Matching Based Audio Deepfake Dataset
Jiawei Du*, I-Ming Lin*, I-Hsiang Chiu*, Xuanjun Chen, Haibin Wu, Wenze Ren, Yu Tsao, Hung-Yi Lee, Jyh-Shing Roger Jang (* equal contribution)
IEEE Spoken Language Technology Workshop (SLT) 2024
DFADD is the first dataset for audio deepfake detection that focuses on speech synthesized by diffusion- and flow-matching-based TTS models, and reveals that current anti-spoofing systems still struggle with these more realistic fake audios.

Neural Codec-based Adversarial Sample Detection for Speaker Verification
Jiawei Du*, Xuanjun Chen*, Haibin Wu, Jyh-Shing Roger Jang, Hung-Yi Lee (* equal contribution)
Interspeech 2024
This paper proposes a neural codec-based method to detect adversarial samples for speaker verification by comparing ASV score differences before and after codec re-synthesis. Experiments across 15 open-source neural codecs show that the approach outperforms seven prior baselines, with Descript Audio Codec giving the best results.
Neural Codec-based Adversarial Sample Detection for Speaker Verification
Jiawei Du*, Xuanjun Chen*, Haibin Wu, Jyh-Shing Roger Jang, Hung-Yi Lee (* equal contribution)
Interspeech 2024
This paper proposes a neural codec-based method to detect adversarial samples for speaker verification by comparing ASV score differences before and after codec re-synthesis. Experiments across 15 open-source neural codecs show that the approach outperforms seven prior baselines, with Descript Audio Codec giving the best results.